
DCGAN、CGAN
DCGAN
DCGAN 框架
DCGAN实在原始GAN的基础上,对于生成器和判别器的模型结构进行了改进,采用可大量的深度卷积代替全连接层。从而提高了处理视觉问题方面上的质量和稳定性。
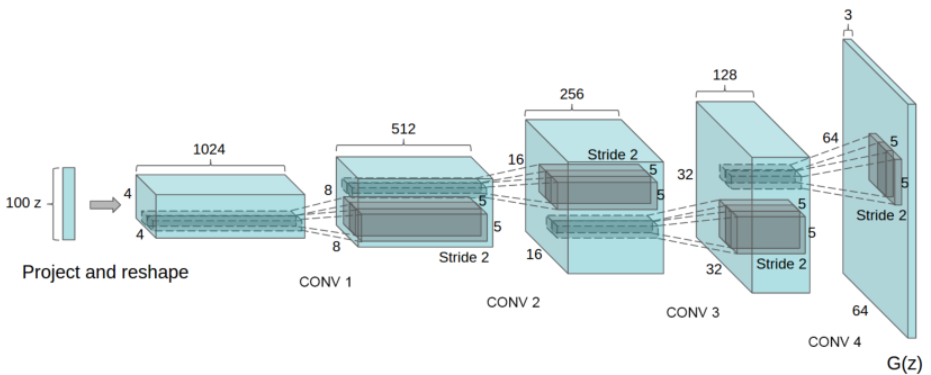
在论文中给出了稳定DCGAN的方法:
- 使用跨步卷积代替所有的CNN中的池化层(卷积—判别器、反卷积—生成器)
- 在生成器和判别器的隐藏层中使用
batchnorm,但是,最后的输出不可以使用(目的:训练更快、更稳定的) - 移除所有的全连接层
- 生成器中的所有激活层都是用的是
Relu函数,除了输出使用的是Tanh函数 - 判别器中的所有激活层都是使用
LeakyRelu函数
DCGAN 训练
论文中的参数推荐
- 所有模型均采用小批量随机梯度下降(SGD)训练,Batch_size大小为128。
- 所有权重均根据零中心正态分布进行初始化,标准偏差为0.02。
- 在LeakyReLU中,斜率均设置为0.2。
- 使用了Adam优化器并调整超参数。基础GAN中建议的学习率0.001太高了,改为使用0.0002。
- 将动量项β1保留在建议值0.9会导致训练振荡和不稳定性,而将其降低到0.5有助于稳定训练。
评估无监督表示学习算法质量的一种常用技术是将其作为有监督数据集的特征提取器应用,并评估基于这些特征的线性模型的性能

使用GANS作为特征提取器对CIFAR-10进行分类(DCGAN不是在CIFAR-10上预训练的,而是在Imagenet-1k上训练的,这些特征用于对CIFAR-10图像进行分类 )实验结果如上表所示
CGAN
CGAN可以视作将GAN重新拉回监督学习领域,我们使用原始GAN以及DCGAN训练时,只需要输入一个随机分布生成的噪音$z$ 即可,但是对于CGAN,不仅要输入一个噪音向量,还需要输入一个label 来控制生成的图片。
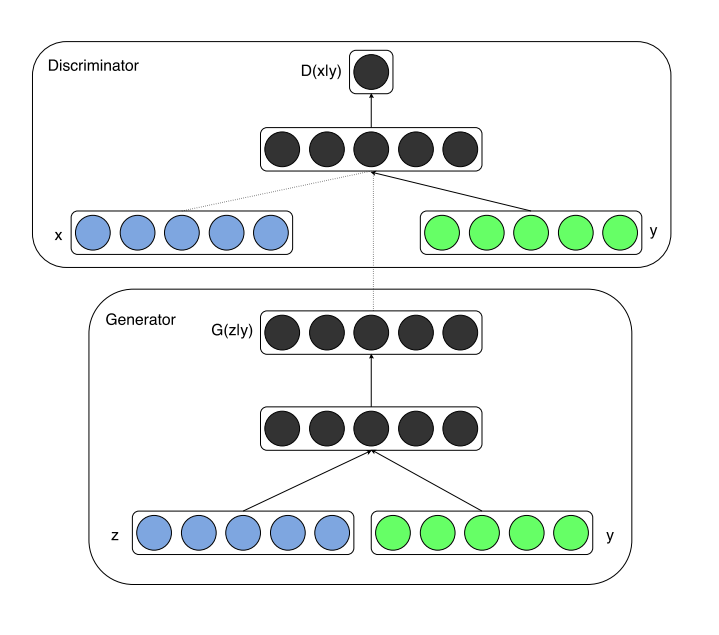
CGAN 框架
- 在生成器中,先验输入噪声 $P_z(z)$ 和 $\boldsymbol y$ 被组合成联合隐藏表示,对抗训练框架在如何组合该隐藏表示方面允许相当大的灵活性。
- 在判别器中,$\boldsymbol x$ 和 $\boldsymbol y$ 被表示为输入和判别器的一个识别参数
我们可以看出,这个于原始GAN的区别为添加了一个前置条件 $\boldsymbol y$ 来控制生成图片的一个方向。
在结构中体现可以观察下图
CGAN 训练
论文是在MNIST图像上训练了一个条件对抗网,条件对抗网以它们的类标签为条件(相当于 $\boldsymbol y$),编码为单热向量(相当于 $\boldsymbol x$)。
生成器和判别器的网络结构这里不在给出,因为现在有一些比论文中给出的结构更加成熟的运算层添加到D和G之中

上图为实验生成的样本展示(每一个对应一个类标签)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Mirclea's blog!



