
StyleGAN
PGGAN
Progressive Growing of GANs for Improved Quality, Stability, and Variation Tero Karras, Timo Aila Published 27 October 2017(Citations 3711) 是 英伟达实验室 Tero Karras 大神提出的生成对抗网络模型,本文的中心思想是通过 Progressive Growing 的训练方法,加速训练过程并稳定模型,并取得非常好的实验效果。同时本还给出了提出了增加图片多样性,减少G和D恶性竞争的方法。以及衡量GAN的指标。
网络架构
这种渐进式的学习过程是从低分辨率开始,通过向网络中添加新的层逐步增加生成图片的分辨率。该种方法主观上允许我们首先学习图片分布的大的结构特征(低分辨率),在机构特征学习之后,逐步学习图片的细节部分(高分辨率),而不是同时学习所有尺度的特征。倘若同时学习所有尺度的特征网络的训练难度过大,试想当图片的大型结构仍需要继续学习,然而细节部分已经学习成功,又出现一个我们不想看到的问题,图片的大型结构一旦改变,网络的细节部分需要重新开始学习。从该角度来看,Progressive Growing 的网络训练架构是相当合理的。
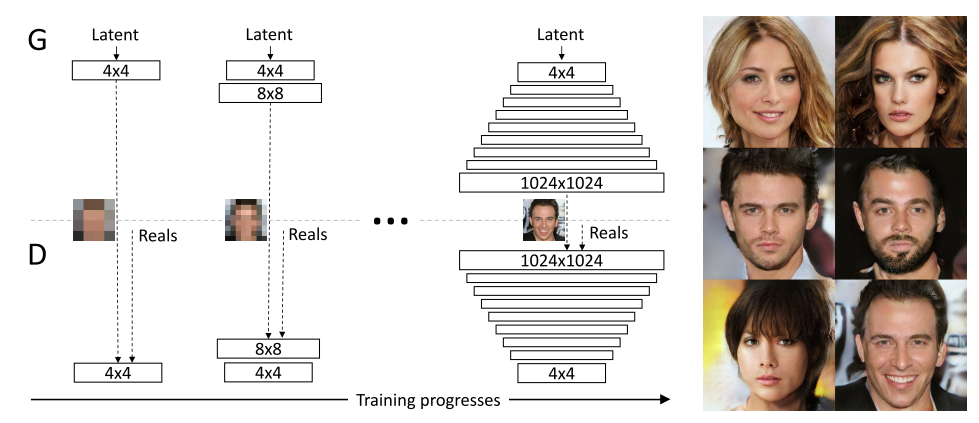
因为网络训练的阶段性,倘若训练16x16直接转移到32x32的网络架构,因为新加入层的网络权重可能”很坏”,网络可能因此坏掉。为了解决该问题,PGGAN 设计了 fade in 的过渡流程。当16x16转移到32x32时,我们通过控制 $\alpha$ 因此,来实现一种渐进的过程,避免网络突然坏掉!

StyleGAN
StyleGAN中的“Style”是指数据集中人脸的主要属性,比如人物的姿态等信息,而不是风格转换中的图像风格,这里Style是指人脸的风格,包括了脸型上面的表情、人脸朝向、发型等等,还包括纹理细节上的人脸肤色、人脸光照等方方面面。具体的可以看上面给的效果视频链接,视频里不同的参数,可以控制人脸不同的“style”。StyleGAN 用风格(style)来影响人脸的姿态、身份特征等,用噪声 ( noise ) 来影响头发丝、皱纹、肤色等细节部分。
- StyleGAN的第一点改进是,给Generator的输入加上了由8个全连接层组成的Mapping Network,并且 Mapping Network 的输出 W’ 与输入层(512×1)的大小相同。
- StyleGAN 的第二点改进是,将特征解缠后的中间向量𝑊′变换为样式控制向量,从而参与影响生成器的生成过程。
网络架构
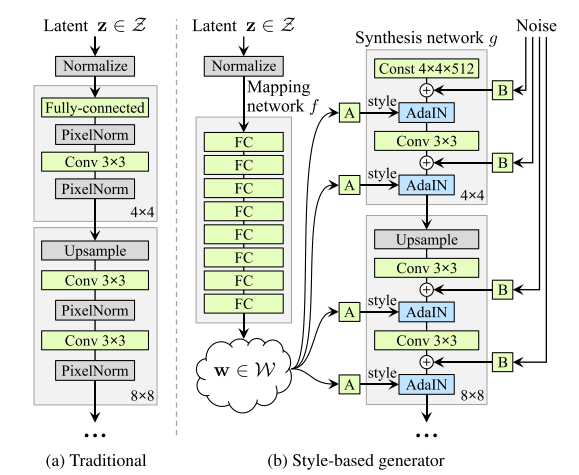
styleGAN的生成器两部分:
- Mapping network $(f)$ : 用于将latent $z$ 转换成为 $w$
- Synthesis network $(g)$:用于生成图像
Mapping network
为输入向量 $z$ 的特征解耦提供一条学习通道
Synthesis network
用于生成图像
删除传统输入
利用 $512 \times 4 \times 4$ 的输入代替传统初始输入。
- 避免初始输入值取值不当而生成不正常图片。
- 有助于减少特征纠缠
随机变化(添加噪声noise)
人们脸上有很多小特征,比如雀斑、发髻线的准确位置,这些都可以是随机的。将这些小特征插入GAN图像的常用方法是在输入向量中添加noise。
为了控制噪声仅影响图片样式上细微的变化, StyleGAN 采用类似于 AdaIN 机制的方式添加噪声(噪声输入是由不相关的高斯噪声组成的单通道数据,它们被馈送到生成网络的每一层)。 即在 AdaIN 模块之前向每个通道添加一个缩放过的噪声,并稍微改变其操作的分辨率级别特征的视觉表达方式。 加入噪声后的生成人脸往往更加逼真与多样。
自适应实例归一化(AdaIN)
特征图的均值和方差中带有图像的风格信息。所以在这一层中,特征图减去自己的均值除以方差,去掉自己的风格。再乘上新风格的方差加上均值,以实现转换的目的。StyleGAN的风格不是由图像的得到的,而是w生成的。
其他细节
样式混合(通过混合正则化)
进一步明确风格控制(训练过程中使用)
在训练过程中,stylegan采用混合正则化的手段,即在训练过程中使用两个latent code w (不是1个)。通过Mapping network输入两个latent code z,得到对应的w1和w2(代表两个风格),接下来为它们生成中间变量w’。然后利用第一个w1映射转换后来训练一些网络级别,用另一个w2来训练其余的级别,于是便能生成混合了A和B的样式特征的新人脸。
低分辨率的style控制姿态、脸型、配件比如眼镜、发型等style,高分辨率的style控制肤色、头发颜色、背景色等style。
Truncation Trick
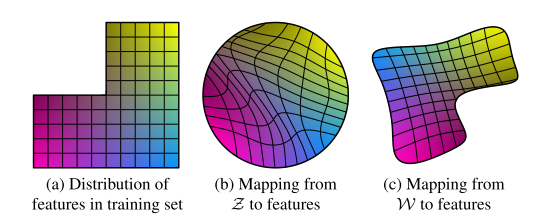
从数据分布来说,低概率密度的数据在网络中的表达能力很弱,直观理解就是,低概率密度的数据出现次数少,能影响网络梯度的机会也少,网络学习到其图像特征的能力就会减弱。
首先找到数据中的一个平均点,然后计算其他所有点到这个平均点的距离,对每个距离按照统一标准进行压缩,这样就能将数据点都聚拢了(相当于截断了中间向量𝑊′,迫使它保持接近“平均”的中间向量𝑊′ 𝑎𝑣𝑔),但是又不会改变点与点之间的距离关系。

感知路径长度
Perceptual path length :测量在潜在空间中执行插值时图像的变化程度,来了解隐空间到图像特征之间的纠缠度。
图像生成其实是学习从一个分布到目标分布的迁移过程,如下图,已知input latent code 是 $z_1$,或者说白色的狗所表示的latent code是 $z_1$,目标图像是黑色的狗,黑狗图像的latent code 是 $z_2$。图中紫色的虚线是 $z_1$ 到 $z_2$ 最快的路径,绿色的曲线是我们不希望的路径。
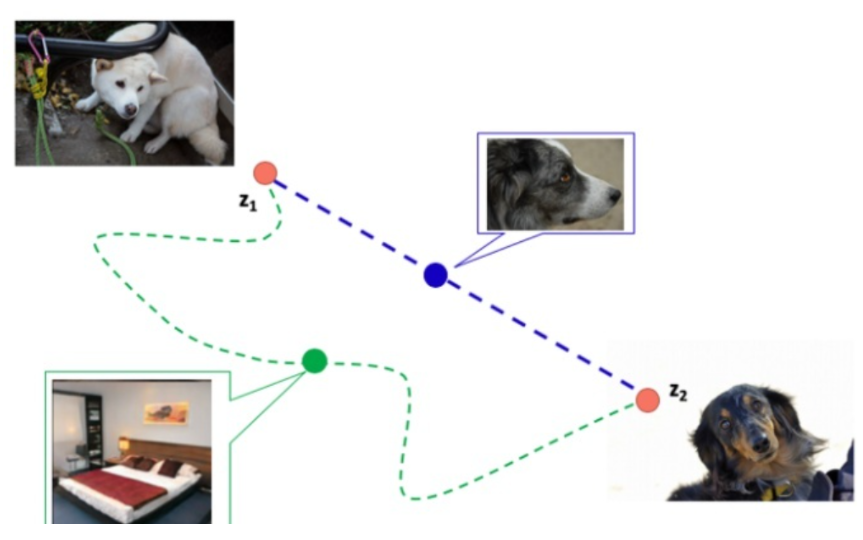
Perceptual path length 是一个指标,用于判断生成器是否选择了最近的路线(比如上图紫色虚线)
(1) 使用两个VGG16提取特征的加权差异来表示一对图像间的感知距离。
(2) 将潜在空间插值路径细分为线性段,每个段上的感知差异的总和就是感知路径长度。
(3)使用多份样本,分别计算z和w的PPL(感知距离长度)。由于z已经归一化,所以对z使用球面插值 slerp,而对w使用线性插值 lerp。评估为裁剪后仅包含面部的图像。
线性可分性
训练特征,方便之后面部编辑,操纵图像特征,比如将男性图片变为女性
如果隐空间与图像特征足够解耦,那么隐空间中存在线性超平面,可以二分类两种特征。在stylegan的文章中,基于CelebA-HQ数据集,训练40种特征的分类器。然后用生成器生成200000张图像,用训练的分类器分类,去掉置信度最低的一半,得到隐变量和标签已知的100000张图像。对每个属性,用线性SVM拟合预测z的类别,判断z是否足够线性。线性关系用X和Y的分布差异衡量。
结论:增加mapping network的深度确实有助于提高w的线性可分性。映射网络对传统生成器有同样的提升,具备通用性。



